The old-school wisdom about learning a language focuses a lot on rules. Language textbooks start each chapter with a list of vocabulary and then proceed into sections, each describing a different grammatical pattern to puzzle over. Conjugations and plurals are laid out in tables telling you how the right word should be chosen at the right time, with their exceptions on the margins in little warning boxes. When you reach the end of the chapter, a common expectation is that you can now solve the language like it’s a complicated math problem. Proof of this may be requested with a long list of exercises, waiting for you to test how well you follow instructions.

The issue with this is it’s hard to learn a language using only the rules. We don’t have the reasoning and memory speed to solve sentences like math exercises - our meat-brains trudge through manually assembling speech with confusion and inelegance. The default way everybody learns language is through intuition. You don’t sit down with your baby and give them grammar lessons. You just hang out with them and trust that the millions upon millions of sentences they soak up will do the heavy lifting for you.
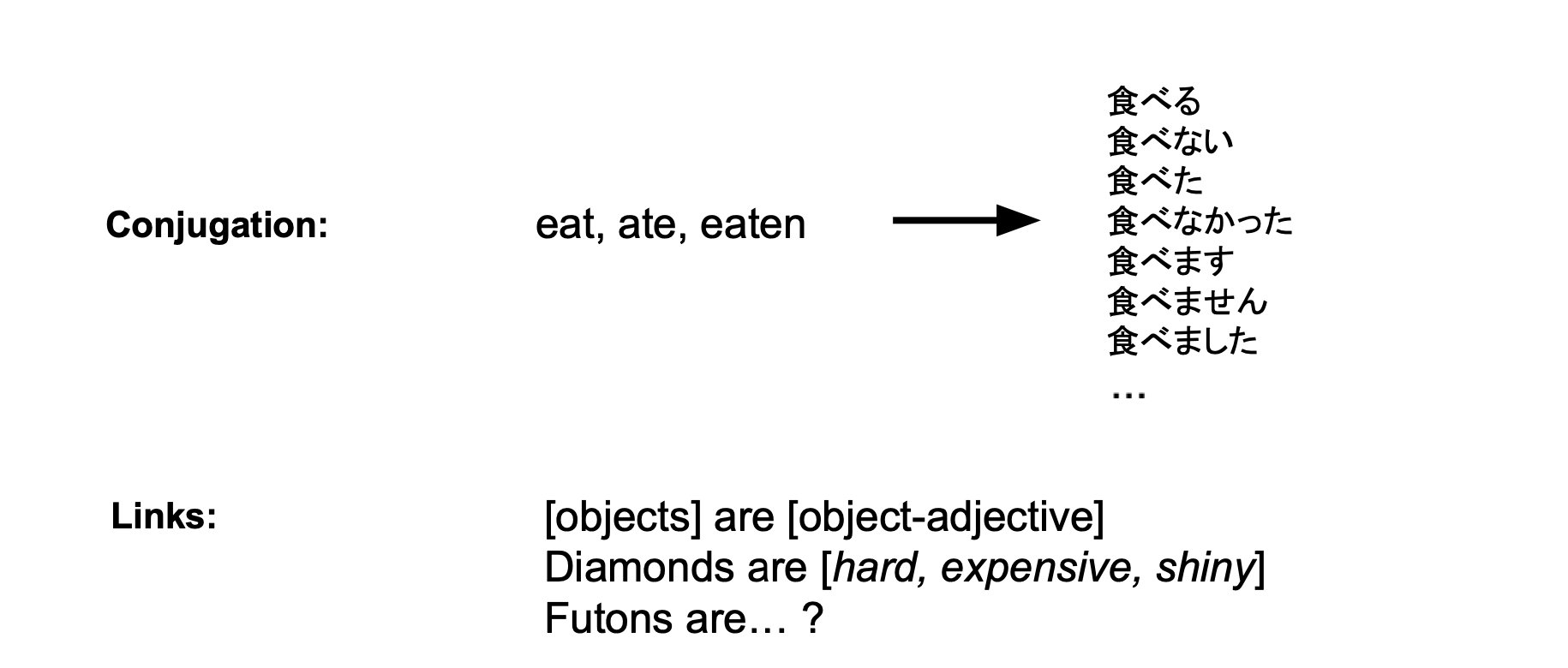
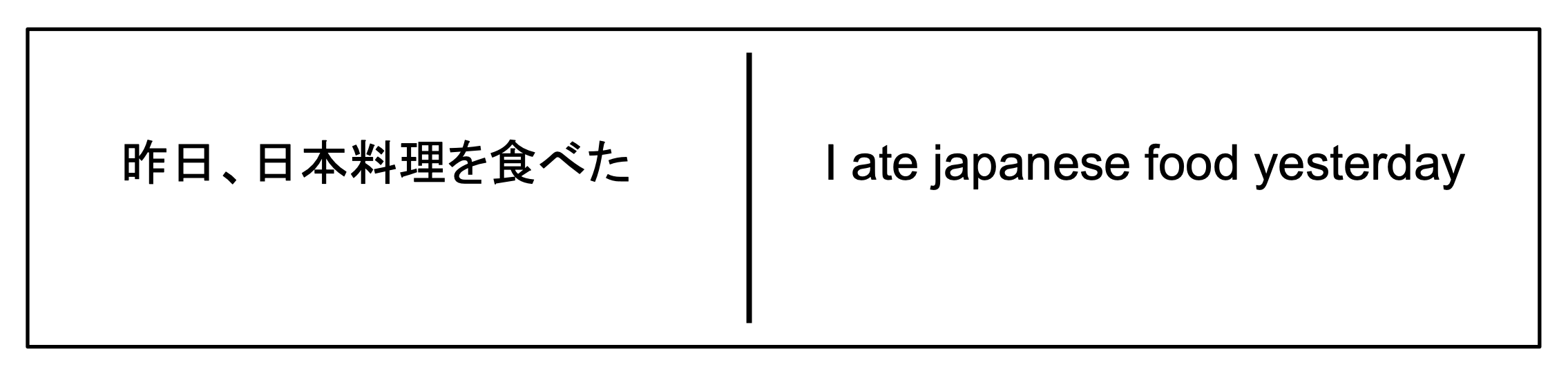
In 2019 I started trying to write software to emulate this abundance-based learning. Over the decade prior I’d tried lots of apps advertising “immersion” but found most were layering minigames over 15-30 example sentences per chapter, the same as textbooks - enough variation to learn the rules, but not enough to get the gist. The alternative I wanted to try was generating sentences, swapping out words for nearby equivalents that wouldn’t mess up the grammar. No textbook or app author was going to sit down and write out a thousand examples per chapter, but with the right syntax, software might be able to match that immersion level of sentence volume - provided, of course, that the sentences made sense.

Generating sentences has both pros and cons. Language is complicated, which means the generator is complicated: outputted sentences need to be both grammatically valid and not conceptually nonsensical, requiring an internal syntax that can work with concepts like conjugation, plurals, and word associations. A human still has to write study material for that generator, and it’s hard work. Textbooks include exercises with the expectation that the student will grind through the rules and create more examples than what the chapter originally provided - if instead you want to create those examples upfront to immerse the student, all that complex sentence construction now falls on the author.
Luckily, the benefits quickly become clear. Templates scale exponentially, generating huge numbers of sentence variants with each replaceable field added. A lesson generator can track vocabulary and grammar independently of specific sentences, and each new word learned will propagate to previous sentence templates to increase variety even more. An introductory language deck with 100 templates can have over a million sentence variations. The resulting software has no need for minigames - it’s a flashcard app that shows you brand new sentences every day, keeps track of what you know, and trusts that volume will enable your language intuition just like it did for your first language.
In the years I’ve worked on this project, I’ve found it interesting how machine translation software has also transitioned from learning with rules to learning with volume. The old AI programs of the 90s tackled language with tables and decision trees, trying to encapsulate the variety of language into simple yes-no logic. The results were comically terrible - words were mixed up, context was ignored, and nuance was forgotten, or worse, inverted. It’s only recently that machines have become gifted at language with a brute force statistical approach. Large Language Models bypass linguistic rules and focus only on volume, training on billions upon billions of examples until they obtain a statistical intuition for how language should sound.
Our brains aren’t direct counterparts to any kind of software, but it should be obvious that they function closer to the latter approach. Textbook authors do their best to make a rules approach work, and with the right teacher, a classroom environment may be excellent and effective - but not everyone has this opportunity. Immersion is how everyone learns their first language, and learning new ones shouldn’t just be restricted to those with an excellent tutor or those lucky enough to study for years in a distant country. Learning through abundance isn’t magic, you just need the abundance. It doesn’t matter where you get it.
Lacuna is a collection of my past few years of work on generators and quiz programs into a web-app. It’s currently in a private pre-alpha. In the next few posts, I’ll try to talk about how it works in a little more detail.
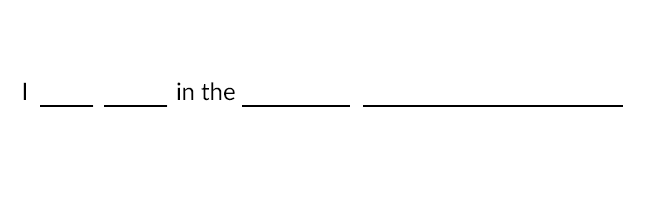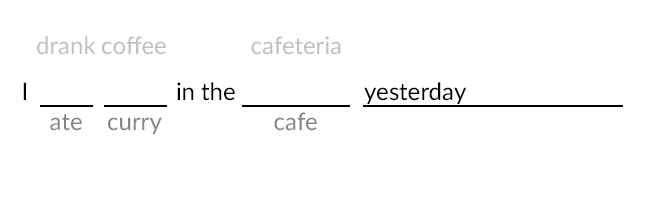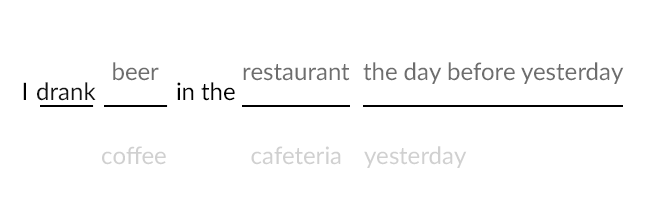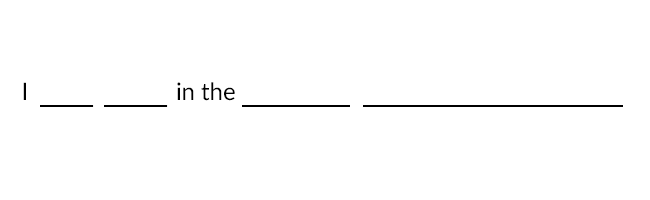
In my research before buying the Light Phone II, a browserless e-paper device on the premium end of “dumbphone” options, I was surprised by how few of its reviewers had decided to stick with it.
Jordan Hart of Business Insider gave it only a week. Unconvinced by the company’s founders, The Verge’s Michael Zelenko asked around; only the crunchiest-granola of friends said they’d try it. CNET’s Jessica Fierro was inspired by the concept, but didn’t make the switch, citing the social media demands of their work. Fast Company and The Guardian gave tepid scores, and Mashable’s Gen Z reviewer could hardly hide their disgust with the device by the end of the week. Common complaints included the tinny voice calling and unusual form factor, an absence of quick navigation, and missing out on texted photos of weddings and vacations. There was a sense that the light phone was an aesthetic; something that a wealthy tech hipster might aspire to have, rather than being genuinely appropriate to use.

It’s a good reminder that not everyone is me. The reviewers didn’t think they needed the phone - they were curious, maybe, but for them it was a device, and as a device the features were lacking. Their complaints were reasonable, from that perspective. But I didn’t find them especially relevant, because for me, buying the lightphone feels like breaking the glass on a fire extinguisher. I’m using the Light II because my smart phone is fucking me up.
Put aside the evidence that the presence of smartphones has cut our attention spans to sub-goldfish levels, or that just having them nearby causes a significant reduction in your cognitive capacity, or that excessive passive screen use might lead to increased dementia risk. The only justification I need for this switch is that smartphone makes me miserable every single day. I’m tired of wasting my mornings wading through misinformation and seething, scissor-statement-esque, over political ragebait. I hate jolting out of an internet hole at a visibly different time of day than when I started, with no clear memory of why I got on in the first place. Long stints leave me feeling dizzy and dissociated, with a
lingering worry that I’m causing permanent damage. Maybe there are hipsters out there buying the phone just for the aesthetic; for me, it’s a pretty slipcover over life-saving medication.
In other words, I’m ready to use the Light Phone II forever. Or at least until it breaks - it doesn’t seem quite as invincible as a Nokia - but, point is, a permanent lifestyle change to a less capable everyday communcations device. It turns out this takes some planning, in practice. One big obstacle is that the entire world now has complete confidence that you have a smartphone, and not meeting that expectation can cause serious problems. It only took a few seconds to realize I would need to have a “wifi smartphone” on deck, or face giving up travel navigation, crucial work-related mobile authenticators, and even the ability to do laundry in my city apartment.
I ended up plotting all my smartphoney tasks on paper, planning how a minimalist phone lifestyle would work in practice. Many apps were either the exact kind of thing I was trying to avoid, or conveniences I didn’t mind giving up. Browser access was obviously first to go, same with social media and games. Extra Chipotle reward points and Spotify access were also not tragedies - a few lost burrito-bucks and reverting to my computer for music, no biggie. Some things could be easily compensated, like carrying a proper flashlight and getting a proper camera, and others were genuine pain points I’d just have to accept, like extra cash to cover for not having Venmo on hand. Some bummers, all doable.

And as for the Big Unavoidables, thankfully it seems like they’ll all be manageable through the Light Phone’s easily accessible hotspot. I don’t love having my iPhone in my bag, even in its new SIM-less state, but on days where I’m not reaching for a mobile auth app for web dev or trying to navigate to a Meetup bar, I can just as easily leave it in my car. I’m already noticing a difference in my information cravings, anyway; the inconvenience of having to pull my old phone out of the bag and fiddle with the settings is enough to discourage trivial interactions.
I do wonder if any of the Light Phone’s critics will ever end up revisiting their assessments of digital minimalism, given the growing sense that the internet is only getting worse. I’m puzzled by how people can be so resentful of doomscrolling and internet holes, but don’t consider confronting the issue the way they might with sudden weight gain or a drinking problem. Often these conversations are mixed with self-deprecation. “I have a terrible internet addiction”, goes the confession, “but it’s only because I’m garbage”.
Switching my SIM card from the iPhone SE to the Light II took weeks of Verizon phone support; the pages long guide on Verizon setup from the Light manufacturer only hammers home that the powers-that-be don’t want you to switch. The companies that make these things have a grip like a vice, so if you’re garbage for falling for their shenanigans, you’re in good company. I’ve considered dropping to a dumbphone for over two years, but was hampered each time by poor phone options and a lack of stock - my current purchase was finally enabled by a New Yorker feature on DumbWireless, a company specializing in guiding tech-free aspirants through the hostile and byzantine process of making their phones less capable. The feature by a major magazine had me hopeful. If there’s money to be made on
stepping back, it might give this cottage industry some needed momentum; I’d still love to buy myself an e-paper typewriter that’s a little less trashy than mine.
In any case, I finally got through my setup difficulty, and I’m now on week three of using the Light. As per the plan, there are some inconveniences, but luckily no dealbreakers. For long car trips, I set up the hotspot and take an extra phone battery; I fidget and sketch in long meetings. I’m reading considerably more every day. My car is quiet on the way to work, and I’m helplessly bored as I wait for coffee at the nearby cafe.
It’s restrictive, but I do feel lighter. You might, too.
I’ve been working on Circuitpython for about a year and a half now, contributing to the module code that helps users access chip features. 2020 was tough, but this community has been a refuge against the worst parts of the pandemic, and I feel extremely lucky to have gotten to learn and work on so many different things despite other parts of life being put on hold.
Here’s some of the stuff that happened this year:
- I spent the early part of 2020 working on support for the STM32 H7 and i.MX chips, and the later half on modules for the ESP32-S2.
- Some of the stuff I had hoped for got added, like deep sleep/low power features.
- Other stuff didn’t quite make the cut, like merging in Micropython and adding C module support (hopefully we’ll still get to that eventually).
- My personal goal to contribute acommunity library for the Dynamixel servo motor went well!
- My personal goal to add DMA support did not (I got hopelessly tied up in low level message corruption).
- I’d hoped to start a meetup in Boston for Circuitpython. For sad and obvious reasons this could not happen. But the number of interested people was encouraging, and I think it’d be worth it to try again in the future.
I think we did a good job of expanding the platform with some new and highly capable chips — the STM32 H7 with raw power, the i.MX with crazy speed for the price, and the ESP32-S2 with WiFi.
But I think one challenge we faced was providing examples of how to actually apply this capability — this was easier with the ESP32-S2, which quickly inspires all kinds of internet-connected builds, but harder on the i.MX and STM32, which are best suited to more complicated projects that are hard to fit in a Learn guide.
So what would I like to see this year?
- I’d like to see our more powerful chips given new example projects and documentation — big ram-consuming display projects on the H7, fast signal handling on the i.MX, and passed-over features like AudioIO on the F405.
- I’d especially love to see some introductory robotics support:
- STM32 has a machine learning module called CubeAI, which can be used for on-chip machine learning and computer vision. This, or any other ML tool, would be super cool to implement.
- A ROS (Robot Operating System) messaging interface would open up Circuitpython microcontrollers to more advanced robotics teams, and could help beginners get started learning about popular robotics platforms.
- Camera modules on the ESP32-S2 and STM32 chips would open up all kinds of neat projects.
- I’d like to see more advanced servo libraries and display code aimed at robotics use.
- I’d like to see more UI tools — Circuitpython already has some good tools for this, but there’s a lot of potential for new DisplayIO widgets and Touch libraries that could power more complex projects.
- And a final, weirder idea — I’ve been wondering if we should try exposing some of the underlying code we’ve created for Circuitpython for use in C projects. I see the potential for a C API that that mirrors what’s used in Circuitpython, so you can jump into native embedded projects without having to learn a whole new codebase like Arduino. There are some big challenges with this, particularly when it comes to exception handling. But the appeal of being able to switch between chips with C projects as easily as we do in Circuitpython is super appealing to me. I’m hoping to work on my proof of concept more this year.
Outside of these broader dev ideas, I’ll also be plugging away at my various Circuitpython PCB projects, which I think are best summed up by this old quote from Bell Labs back in the 80s:
“The first 90 percent of the code accounts for the first 90 percent of the development time. The remaining 10 percent of the code accounts for the other 90 percent of the development time.”
Whether it’s projects or a pandemic, here’s to a year of wrapping things up.
As we hit the new year, the call has gone out to the greater Circuitpython community to contribute their thoughts, hopes, and projects for 2020. I’m excited to share some of the things I’ve been thinking about for the project.
I was brought on late last summer by Adafruit Industries to build and maintain the STM32 port for Circuitpython, working on the API code beneath the python interpreter that allows users to command the peripherals that power each Circuitpython development board. It’s been a blast working with the team and learning more about the project, as well as inspiring and humbling to witness all the progress that’s been made over this past fall.
But while I’ve spend plenty of time mucking around in the deep wizardry of the STM32 HAL, I’ve never properly been on the user end of Python. The limited experience I do have actually developing with Circuitpython has been pretty exciting; being able to tweak a calibration value or change an algorithm and see those results instantly rather than after 5 minutes of compilation and re-programming is a mind-blowing experience for an embedded C developer. But my python coding skill itself leaves something to be desired, something I’m forced to sheepishly admit on Github issues that straddle the line between Python and my C code.
Thus, one of my favorite people to talk to in my local network is Don Blair, a developer for an open source agricultural tech project who uses Circuitpython full-time for his work. What excites me so much about Don’s projects is the potential for Circuitpython to be a force for good in the world, not just as a teaching tool, but through the actual tangible projects it is used in. I felt a 2020 post wouldn’t be complete without a perspective like this, completely from the user side, and with the end goal of making the world a better place through code. So in preparation for this post, I sat down with him and we did our best to combine our ideas from both sides of the Circuitpython project, from the code.py file down to the bare-metal C and register-driven peripherals that make it all work. Here are some of the things we talked about.
Scientists, Activists, Programmers
Lucian: I think it’s an exciting idea for Circuitpython to be used by people who aren’t necessarily beginners to tech, but are simply beginners in hardware. Even for a seasoned programmer, switching to a microcontroller project from another field is a rightfully intimidating process — there’s a huge volume of material to learn and new skills you need to acquire if you simply jump into the raw C. Arduino made this process easier, but Circuitpython makes it accessible on a whole new level. I’ve found myself recommending Circuitpython to data scientists, environmental activists, and machine learning specialists alike who want or need a hardware component in their projects but can’t simply become embedded engineers on the fly. Python is a language that many of them already know — a 2018 study of 23,859 data professionals found it to be the most popular by far, with 83% of respondents using it
regularly — and Circuitpython gives them the means to use their existing background with a real-world interface, reading sensors, controlling robots, and controlling remote systems.
Like I said before, I’m excited by how these projects spread good past the education phase. I think teaching people new skills is an intrinsic good on its own, but the prospect of Circuitpython helping scientists to diagnose our oceans and farmers to better understand their crop cycles seems like a whole new level of impact to me. In 2020 I hope we can do more to recognize and encourage this kind of Circuitpython use, and I hope to help add new features that better support these kinds of projects.
Don: I’ve been working with environmental scientists and researchers on monitoring projects for several years now, and I’ve learned from many of them how important environmental monitoring has become in land stewardship, wildlife conservation, and in assessing — and figuring out how best to mitigate — the impacts of climate change. And what I keep hearing from these practitioners is that they’re stuck using proprietary, difficult-to-operate, expensive monitoring hardware — often stuff that was designed in the early 90s, and encrypts its data (which could easily be a simple CSV file) so that using the instrument is only possible with an expensive software license — where the software typically only runs on a now-outdated version of Windows.
Researchers and farmers who have been exposed to the world of inexpensive, open source hobby electronics — with its wide range of easily-interfaced devices, connectivity options, and flexible data formats — are amazed by the capabilities they see. But as Lucian says, even the relatively accessible Arduino platform can be intimidating to novices, with the consequence that adoption and development of open source hardware in environmental monitoring applications seems slower than it ought to be. That’s why the truly beginner-friendly approach taken by CircuitPython recently has been such an exciting development for me: there is finally a platform that I can unhesitatingly recommend to farmers, hydrologists, agronomists, and resource managers.
Among programming languages, Python is particularly popular, and particularly easy to understand; and the hardware is often set up so that no special IDE is required — the code can be accessed and modified on the device as if it were a USB stick. This represents a huge leap in accessibility and usability for these communities. A detailed, high resolution picture of environmental dynamics is going to become more and more important in the next few years — we need to make deploying monitoring devices as frictionless and easy for practitioners as possible. I think CircuitPython really has the potential to make this possible, and to become the ‘beginner-friendly’ standard in farming and in scientific research.
A Sleep/Suspend Interface:
Lucian: I’ve worked on a number of low power projects in the last year that need to go months or even years without having the batteries replaced. The current version of Circuitpython doesn’t have much support for this kind of power efficiency — you need to assemble your own external power-off system, which makes for a bigger form factor and requires the device to be hard rebooted. This year I’d like to explore a suspend or Wait-For-Interruptsystem that can smoothly enter and wake from sleep mode, so that Circuitpython devices can enter the Suspend state offered by most microcontrollers that sustains the device memory on only a few nA of power.
This is an essential feature not just for common hobby projects like alarm clocks, battery powered robots, or open-source mobile devices, but also for environmental sensing applications. Many data gathering devices must be left in the field for years at a time and only wake for a few minutes at a time every hour, day, or week. It’s a feature I think would be a practical addition for both sensor/device oriented beginners, and also the academic applications I’m excited about in data science.
Don: Because CircuitPython makes sensor measurements and datalogging so straightforward, I’ve been eager to deploy battery-powered field loggers using CircuitPython firmware. But one immediately runs up against the lack of any ‘low power sleep’ functionality on the CircuitPython hardware. My current method for getting around this when deploying CircuitPython hardware in the field is to use an Adafruit TPL5100 Power Timer breakout, which acts as an external power switch, turning the entire datalogging microcontroller circuit off between logging sessions, and waking up at intervals that are set with a resistor value.
This method works fine, as far as it goes — but it adds cost, and its range of functionality is quite restricted compared to what would be possible if the micro itself was capable of low-power sleep: waking on interrupt in response to an external signal (sensor reading, radio signal, or RTC); storing running parameters in memory rather than e.g. needing to write to flash or SD card; etc. It would be really useful if farmers and researchers who wanted to quickly and easily deploy dataloggers or remote radio nodes in the field could instead simply call a low-power sleep function in CircuitPython.
Dynamically Loaded C
Lucian: when discussing this post, I had a moment with Don where we remarked on how crazy it would be if native C code could be loaded dynamically into a Circuitpython program just by dragging them into the drive. Imagine my excitement when reading the other Circuitpython 2020 posts and learning via Deshipu that Micropython has just recently done this. Circuitpython benefits from a clean shared-bindings API that provides familiar access to basic chip functions across any supported development board. But one downside of this is there isn’t really a conceptual home for modules that are board-specific or so early in development that they haven’t nailed down their API. One way to handle this is to make it easier to add new modules, a process which I’m interested in providing more documentation for.
But I think board specific modules could be an opportunity to expose chip specific features and enable developers to distribute new modules for testing that could later be turned into official additions.
I’d expect this to also be relevant to the use of Circuitpython in scientific applications. I’d love to see the door opened to unique modules like a machine learning or motor driver stack on chips like the i.MX RT, or enabling researchers to use a custom C library for a DSP project that they can’t justify adding to the main API but want to expose to novice researchers for use in environmental sensors. Without more experience, I can’t say with confidence what would and wouldn’t be possible with a system like this, but I’d love to at least explore the concept this year.
Supercharging SPI
Lucian: one less broadly applicable thing I’d like to explore this year is batching data to SPI and other communication methods via Direct Memory Access (DMA), which is relevant to a number of my personal imaging and sensor projects. I think a more advanced native C layer for buffering the inputs and outputs of the BusIO modules would be neat — a setup where python code is used to initialize and diagram a communication system, but not necessarily to run it realtime to save speed. My hope would be to allow things like faster DSP, data storage and DisplayIO outputs, without compromising the beginner focus of the API.
Projects for this year
Lucian: I have a lot of projects I’d like to do, which in conjunction with the above is probably stupidly ambitious. In all likelihood I’ll start a number of things and only keep up with my favorites, as per usual… but here’s my shortlist.
– Adding half-duplex UART and creating a library for the Dynamixel, my favorite kind of servo motor, which uses a shared addressable bus and has some great features like continuous rotation mode, torque detection, auto shutoff, etc. The bonus, of course, will be putting it in a robot.
– Porting my old SPUDwrite project to Circuitpython and open-sourcing it, using the E-paper, keyboard and SD card code. I’d also love to work on some new SPUDs (Single Purpose User Devices). A lightweight, hackable SPUDphone comes to mind…
– Finish the featherwing for my generic breakout board tester.
– Start a Circuitpython meetup here in Boston atArtisan’s Asylum! Hopefully more news on this soon.
Don: I’m planning on continuing to support the CircuitPython projects that we’ve deployed in Portugal (soil moisture monitoring via a LoRa — WiFi gateway, pics here), Nebraska (soil moisture via cellular modem, pics here), Maine (sea level rise — pics here), and on Martha’s Vineyard (tide monitoring, pics here) while continuing to develop more applications for research at sea.
In particular, I’m hoping to further develop and refine the CircuitPython-based satellite modem system that we tested out on the R/V Neil Armstrong (a research vessel based at Woods Hole — pics here) a few months ago, with hopes of using it as the core electronics for a ‘drifter buoy’ system that would temperature of currents off the Northeastern US coast.
We’re also working on the analog front-end for an impedance spectroscopy system that we’re planning on driving with CircuitPython to make it easier for laboratory researchers to get things up and running. In general, CircuitPython is becoming our go-to for making scientific research instrumentation as accessible and easy to understand and modify as possible — we’re really passionate about getting the word out about it, and showing people what’s possible now!
Lastly
I’d like to express appreciation for everyone who’s written Circuitpython 2020 posts so far, they’ve been really inspiring to read! Many of the topics people have brought up, such as package management and automated testing, have been covered so well I didn’t bother to include them here, but I’m super excited to see where they go and help wherever I can. I hope everyone achieves their goals this year, no matter how ambitious — here’s to an awesome 2020 for Python on hardware.



